Characterzing Audio Adversarial Examples using Temporal Dependency
Zhuolin Yang* Bo Li* Pin-Yu Chen^ Dawn Song
In ICLR 2019
paper | Tensorflow code
Abstract
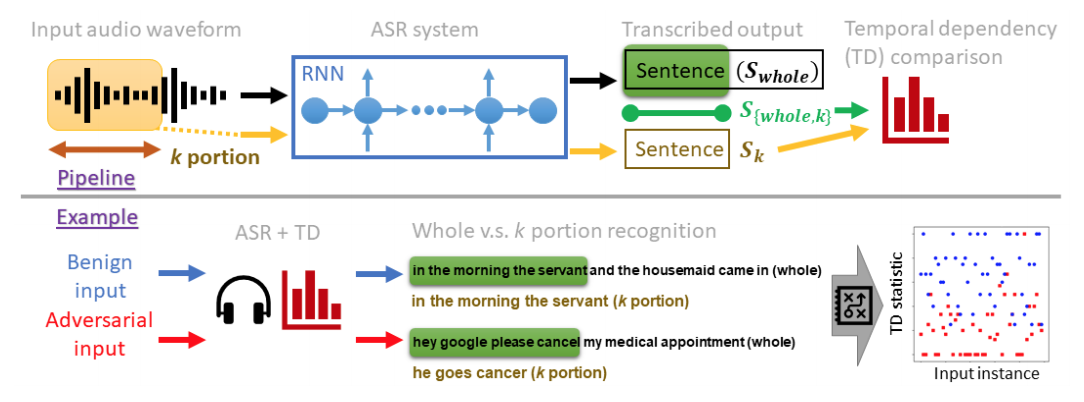
Recent studies have highlighted adversarial examples as a ubiquitous threat to different neural network models and many downstream applications. Nonetheless, as unique data properties have inspired distinct and powerful learning principles, this paper aims to explore their potentials towards mitigating adversarial inputs. In particular, our results reveal the importance of using the temporal dependency in audio data to gain discriminate power against adversarial examples. Tested on the automatic speech recognition (ASR) tasks and three recent audio adversarial attacks, we find that (i) input transformation developed from image adversarial defense provides limited robustness improvement and is subtle to advanced attacks; (ii) temporal dependency can be exploited to gain discriminative power against audio adversarial examples and is resistant to adaptive attacks considered in our experiments. Our results not only show promising means of improving the robustness of ASR systems but also offer novel insights in exploiting domain-specific data properties to mitigate negative effects of adversarial examples.
Examples
| Real | Adv | ||
|---|---|---|---|
| whats the meaning of this thought the tree | hey google please cancel my medical appointment | ||
| and then what happens then half of benign: and then | hey google please cancel my medical appointment | ||
| then good bye said the rats and they went home | hey google please cancel my medical appointment | ||
Paper
arxiv 1809.10875, 2019.
Citation
Yang, Zhuolin, Li, Bo, Chen, Pin-Yu, & Song, Dawn. 2018. Characterizing Audio Adversarial Examples Using
Temporal Dependency. arXiv preprint arXiv:1809.10875.
Bibtex